# 先抛结论
如果日志型ES集群system load 过高,I/O打满,尤其是在读写低谷时间段 read 异常高,可以考虑排查段合并的问题。
如果的确是遇到了段合并问题,可以考虑两个方向:
- 机械硬盘升级为SSD。
- 大索引拆分成小索引。
PS. 再附送一个潜在的查询问题可能导致的IO打满:通配符查询,参见文章。
# 排查
详细的排查过程就不赘述了,无非是加监控,包括业务层面、ES层面、机器层面,然后横向、纵向的分析各种监控指标。
这里分享几个容易被忽略的指标/api
查看最大的索引的 _stats 中merge部分:
total_stopped_time_in_millis :通常应该是0
total_size_in_bytes:总共merge了这么多数据,你会发现远大于索引大小。下文会介绍这一指标。
观察线程状况,api详细参数可以查阅官方文档。我在定位问题时还不知道hot_threads这个api,如果提前知道的话可能就省下不少时间了。
1 2GET _cat/thread_pool?v GET /_nodes/hot_threads
# 原理
段合并的基本原理很简单,两个(多个)已提交的段写入一个新的段。
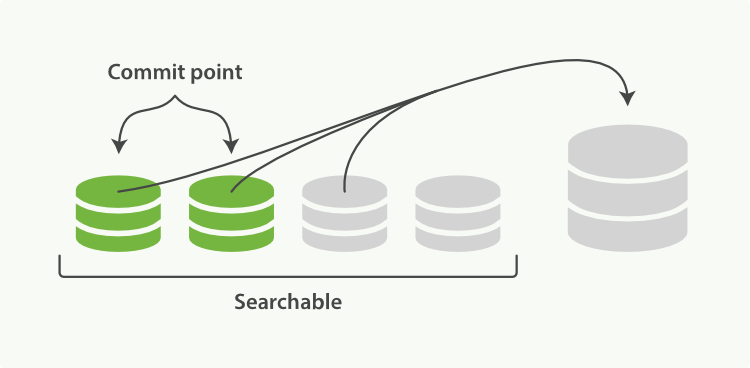
这种读写除了尚在内存中的部分,就难免需要消耗磁盘IO了。
而从可视化Lucene段合并一文中得知,这种类似于SSD写放大的过程其实是一种浪费(文中称为tax),一个最终1G的索引可能由于merge而需要读写10G磁盘。
段合并算法优化的一个目标就是降低这种浪费,更高效地做段合并。
而减小我们索引的体积就可以轻松的带来显著的提升。
